Duplicate Detection

What is Duplicate Detection?
Duplicate Detection helps teams identify and reduce overlapping content in Guru. It automatically scans your knowledge base for Guru Cards that are highly similar and flags them as potential duplicates so you can clean up redundant content before it causes confusion.
This feature is especially useful for teams with multiple authors or fast-growing content libraries. Instead of manually reviewing every Guru Card, Duplicate Detection gives authors a focused view of what needs attention, making it easier to streamline info and reinforce accuracy.
How it works
Scans for similar content weekly
Guru automatically reviews your account every Monday once you’ve published over 100 Cards. It compares content using a similarity threshold of 90% to identify potential duplicates.
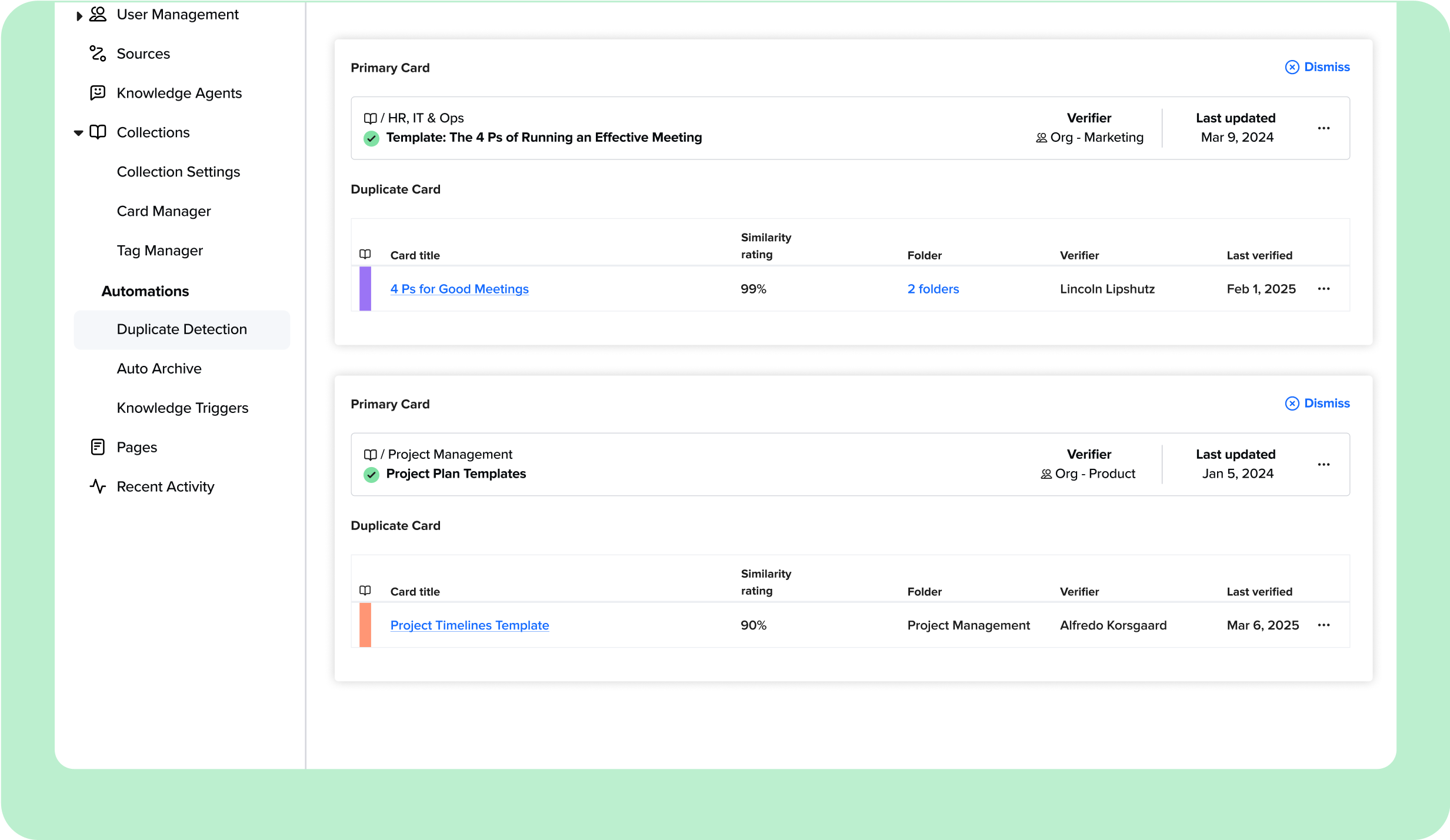
Displays grouped duplicates for easy review
Authors see duplicate suggestions grouped together in a dedicated dashboard. Each group contains Guru Cards with overlapping content that surpass the similarity threshold.
Only shows content you can edit
Users only see duplicate groups for Cards they have edit access to, keeping the review process simple and secure.
Dismiss and revisit later
If a duplicate group is dismissed, it will reappear after two weeks if the Cards still meet the similarity threshold. This gives teams time to evaluate and act without losing track of duplicate content over time.
Why it matters
Protect your single source of truth
When your team sees multiple versions of the same info, it’s hard to know what’s accurate. Duplicate Detection helps ensure that only the most up-to-date, verified knowledge is used.
Save time for authors and admins
Instead of spending hours auditing content manually, Authors can quickly act on Guru’s suggestions—freeing them up to focus on creating valuable, net-new knowledge.
Secure data control
Duplicate Detection respects your team’s permissioning model. Users only see duplicate suggestions for Cards they have edit access to, and actions like deleting or merging content remain within their assigned roles. Because flagged Cards retain their verification status, teams can easily prioritize which versions are trusted and which may need cleanup. Every edit and dismissal is tracked, ensuring full visibility for knowledge managers and Admins. Learn more about how Guru protects data on our security page.
Learn more about...
Knowledge Agents & AI answers
FAQs
You’ve got questions, and we’ve got answers.
Guru runs its Duplicate Detection process once a week, every Monday morning — but only for teams that have more than 100 published Cards. This helps keep your knowledge base clean and easy to navigate without requiring constant manual oversight.
Guru uses a 90% similarity threshold to flag content as potentially duplicative. If two or more Cards exceed this threshold, they’ll appear grouped together in the Duplicate Detection dashboard for review by users with edit access.
When you dismiss a duplicate group, it’s hidden for two weeks. After that, if the Cards in the group still exceed the 90% similarity threshold, they will reappear in your Duplicate Detection dashboard.
Yes, Guru displays a maximum of 20 duplicate groups at any given time. This keeps the dashboard manageable and focuses attention on the most pressing or obvious duplications first.