Rethinking Your Knowledge Base Architecture: Why Bite-Size is Best
Wenn Sie sich auf Control-F verlassen, um in mehrseitigen Dokumenten in Ihrem Unternehmenswissensrepository zu suchen, ist es an der Zeit, Ihre Wissensarchitektur vollständig zu überdenken – und sich in Richtung kurzformatiger, leicht konsumierbarer, diskreter Wissensstücke zu bewegen.
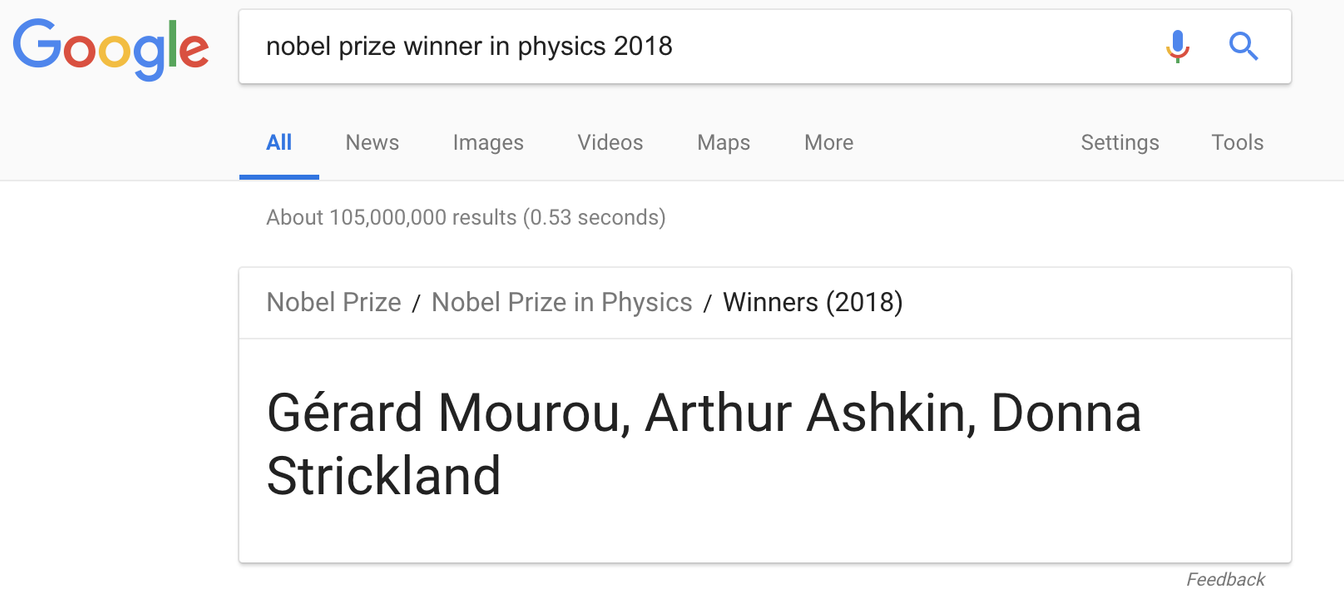
Als Google 2012 sein Knowledge Graph auf den Suchergebnisseiten (SERPs) einführte, wurden seine Featured Snippets (diese kurzen, relevanten Datenpunkte, die ganz oben auf der Seite angezeigt werden) zur ersten Anlaufstelle für alle, die eine schnelle Antwort benötigten. Stark auf das Scraping von Daten von Seiten wie Wikipedia angewiesen, konnte Google Daten nutzen, die von anderen zusammengestellt wurden, um Sie in ihrem Ökosystem zu halten – ein Segen für einen werbegestützten Einnahmestrom. Aber etwas anderes geschah ebenfalls: der Verkehr zu Wikipedia nahm ab. Während jeder Statistiker im Recht wäre, uns daran zu erinnern, dass Korrelation nicht gleich oder impliziert Kausalität, können wir auch unser eigenes Verhalten betrachten, um einen Eindruck davon zu bekommen, was passiert ist. Wenn alles, was Sie wissen müssen, sagen wir, wer in diesem Jahr den Nobelpreis für Physik gewonnen hat und die Antwort ganz oben auf der Seite steht, ist es nicht nötig, weiter durch die anderen 105 Millionen Ergebnisse zu suchen.
Wir wissen das instinktiv, aber wenn es um unsere Wissensportale geht, richten wir sie oft so ein, dass sie als Archive fungieren, anstatt als Möglichkeit, die Informationen, die wir benötigen, leicht anzuzeigen. Deshalb – und das könnte schwierig zu hören sein – müssen wir unseren gesamten Ansatz komplett überdenken.
Wenn Ihr Unternehmenswissensportal wie die meisten ist, müssen Sie bei einer Frage a) genau wissen, wonach Sie suchen, oder b) Sie müssen durch Hunderte (oder Tausende!) von Wörtern in mehrseitigen FAQs oder PDFs suchen, um eine Antwort zu finden, die irgendwo in ihnen vergraben ist.
Control-F war entscheidend, um dieses Setup zu ermöglichen, aber warum sollten Sie eine effektiv als Umgehung betrachtete Methode verwenden, nur um eine einfache Antwort zu erhalten? Es liegt nicht nur an dem Mitarbeiter, das Wissen auszubuddeln (was einen nicht unerheblichen Zeitraum in Anspruch nehmen kann), es bedeutet auch, dass jedes Mal, wenn sich etwas an diesem Wissen ändert, das Unternehmen ein völlig neues PDF, Video oder eine FAQ hochladen muss. Das verschwendet Zeit – und Budgets.
Die bessere Lösung ist, Ihre Wissensarchitektur vollständig zu überdenken und sich in Richtung kurzformatiger, leicht konsumierbarer (und aktualisierbarer), diskreter Wissensstücke zu bewegen.
Suche und Rettung
„Schau, es ist nicht so schlimm“, sagen Sie wahrscheinlich gerade, „es erfüllt seinen Zweck!“ Also lassen Sie uns darüber sprechen. Das ist nicht einmal das erste Mal, dass wir darüber auf dem Guru-Blog gesprochen haben. Vor fast drei Jahren haben wir darauf hingewiesen, dass:
Vertriebler verbringen bis zu ein Drittel ihrer Tage, um Informationen zu suchen, die sie für ihre Arbeit benötigen. Informationen werden bei Bedarf benötigt, und die aktuellen Lösungen sind nicht für eine On-Demand-Welt ausgelegt. Dokumente und Wikis zwingen Sie dazu, Control+F zu verwenden, um Wörter zu finden, und lassen Sie dann die Antworten selbst zusammenpuzzeln.
Wenn Sie mit einem Kunden chatten und eine Frage beantworten müssen, haben Sie nicht die Zeit, um den aktuellen langen und ineffizienten Prozess zu durchlaufen, um die Antwort zu finden. Sie suchen das Dokument, das die richtige Antwort haben sollte, öffnen dieses Dokument, suchen nach einem Schlüsselwort, und nach all dem erscheint nicht Ihre Antwort, sondern Sie sehen, dass das Wort, das Sie eingegeben haben, fünfzehn Mal erscheint. Um die richtigen Informationen zu erhalten, müssen Sie alle Optionen durchklicken, während Ihr Kunde auf seine Antwort wartet.
Aber es geht über das bloße Verschwendet wertvoller Sekunden hinaus. Längere Inhalte sind einfach schwieriger zu durchsuchen als kürzere Inhalte. Lassen Sie uns das aus dem Bereich des Wissensmanagements herausnehmen und in einen Bereich bringen, mit dem wir uns alle identifizieren können: wie wir mit Inhalten zu Freizeitzeiten umgehen.
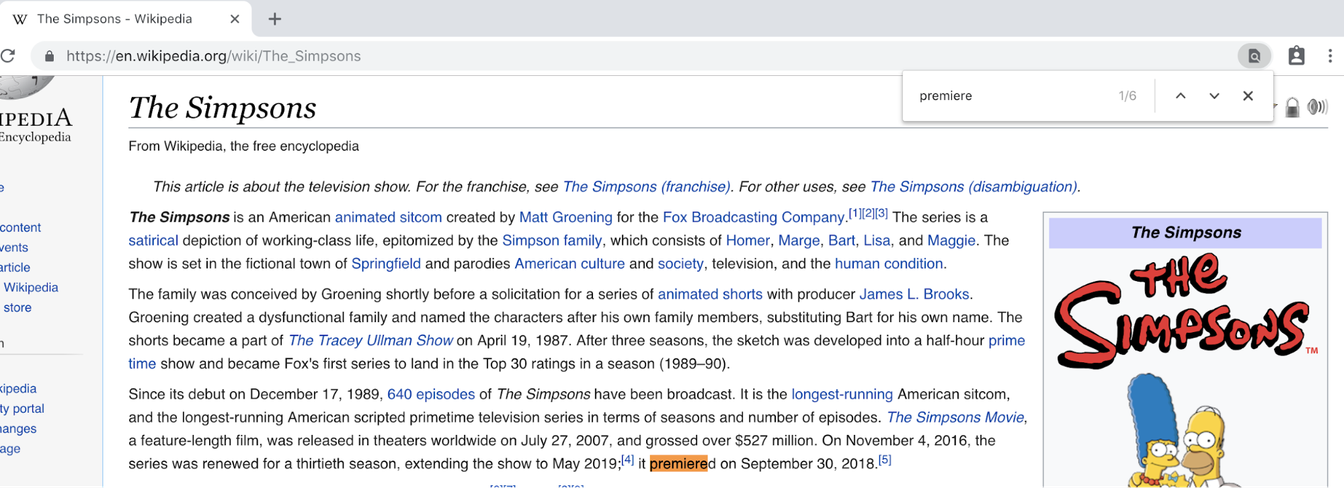
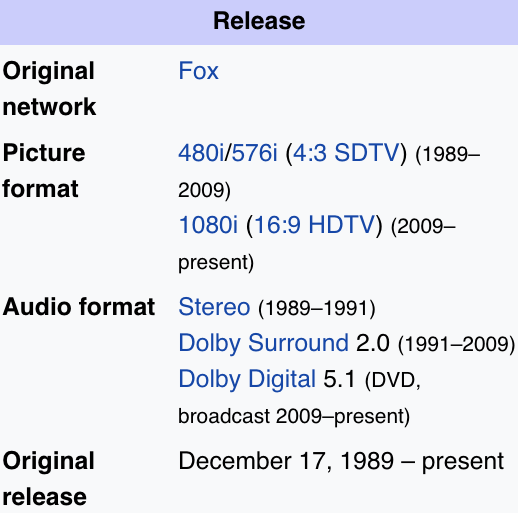
Hier ist eine Frage, deren Antwort Sie vielleicht wissen oder auch nicht: In welchem Jahr hatte Die Simpsons Premiere? Sie ziehen Wikipedia auf, geben „Die Simpsons“ ein und erhalten diese Seite mit über 17.000 Wörtern. Sie verlassen sich auf Ihr bewährtes Control-F und suchen nach „Premiere“ und das passiert:
Warten Sie, was? Stellt sich heraus, dass Sie nach „Release“ suchen mussten:
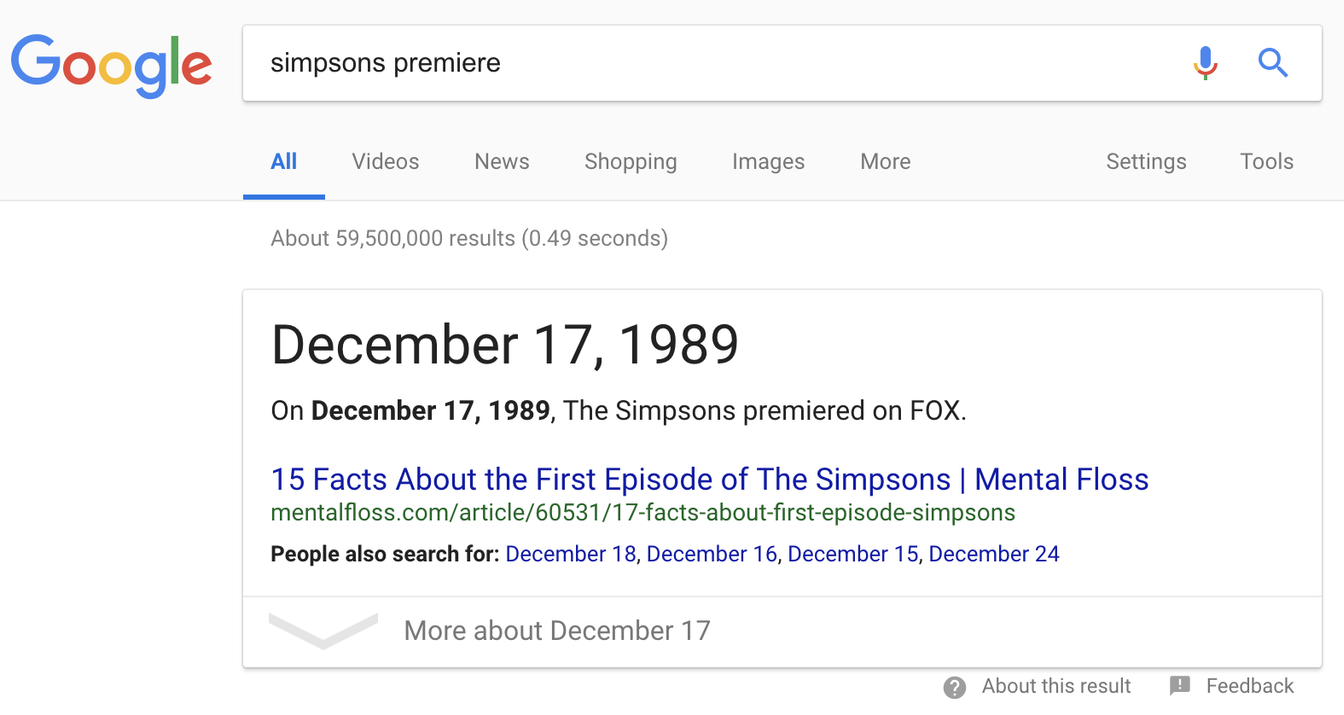
Nicht nur mussten Sie genau wissen, wie diese (hochorganisierte, sollten wir anmerken) Seite aufgebaut ist, sondern Sie mussten auch genau die Terminologie kennen, die die Autoren verwendet haben, um ein Startdatum anzugeben. In der Zwischenzeit, wenn Sie zu Google gehen und einfach „Simpsons Premiere“ eingeben, erhalten Sie dies:
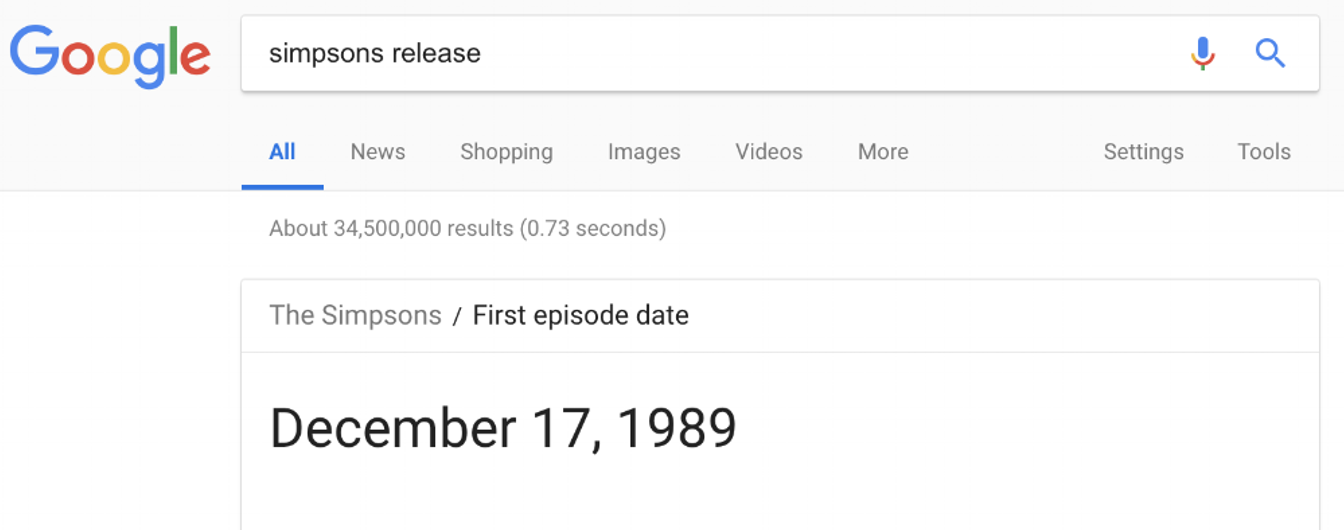
Suchen Sie nach „Simpsons Veröffentlichung“ und Sie erhalten dieselben Informationen, wenn auch etwas anders dargestellt:
So oder so ist das Ergebnis hilfreich, schnell und vor allem unabhängig von der genauen Formulierung, die Sie verwendet haben, leicht zu finden. Sie mussten nicht einmal Control-F verwenden.
Ich habe immer noch nicht gefunden, was ich suche
Jetzt lassen Sie uns diese Diskussion wieder auf das Wissensmanagement lenken. Ihre eng gedruckten PDFs mit einer Schriftgröße von 10pt und FAQ mit 48 Punkten sind großartig – um Druckkosten zu sparen. Sie sind nicht ideal, um sich genau auf das zu konzentrieren, was Ihre Mitarbeiter wissen müssen, egal ob es sich um Informationen zu Leistungen bei der Einarbeitung, Produktdokumentation zum Launch oder sogar darum handelt, das richtige Informationsblatt zu finden, das verteilt werden soll.
Lustigerweise, je mehr wir unser Wissen digitalisiert haben, desto mehr mussten wir auf Umgehungen zurückgreifen, um das, was wir finden mussten, tatsächlich zu lokalisieren. Diese vielgehassten Lehrbücher Ihrer Jugend? Das Register war der Teil, mit dem Sie die meiste Zeit verbracht haben. Schließlich sagte es Ihnen genau, wo Sie finden konnten, was Sie benötigten – und was Sie ignorieren sollten – und beinhaltete normalerweise auch kontextuelle Aufschlüsselungen (z. B.: Die Mondlandung, die Reaktion der UdSSR darauf).
Jetzt? Wir machen uns Arbeit, die Computer und KI effizienter erledigen können, wenn wir sie nur lassen. Ihr Wissen in mundgerechte Portionen zu speichern bedeutet, dass jede kontextuelle Suche viel schneller geschehen kann. Viele Unternehmen sprechen über ihre Maschinenlern- und KI-Fähigkeiten in der Unternehmenssuche – aber all diese Lösungen sind nutzlos, wenn sie nur ein 30-seitiges Dokument anzeigen können, das Ihre Mitarbeiter immer noch durchsehen müssen.
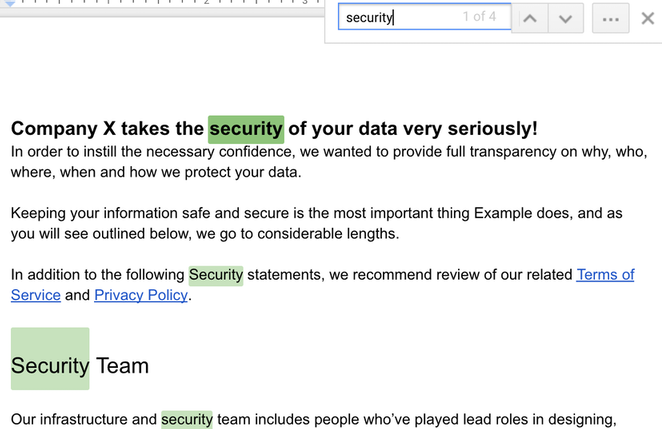
Wenn Dokumente nicht zum Drucken bestimmt sind, gibt es keinen Grund, sie nicht in einzelne Komponenten zu unterteilen, um eine bessere Wissensreferenzerfahrung zu ermöglichen. Andernfalls zahlen Sie als Unternehmen möglicherweise Ihre Mitarbeiter dafür, dass sie die manuelle Arbeit des Durchsuchens von 50 hervorgehobenen Vorkommen des Wortes „Sicherheit“ in einem Produktdokument erledigen – und sie finden möglicherweise immer noch nicht, wonach sie suchen, weil sie nicht mehr Kontext in eine Control-F-Suche einbringen können.
Dieser Ansatz kommt nicht nur denen zugute, die Wissen hinzufügen und pflegen; es hilft auch Ihrem Vertriebsteam enorm. Wenn ein Verkäufer versucht, einen Deal abzuschließen, möchten Sie dann, dass sie sofortigen Zugriff auf spezifische Informationen haben oder... einen Suchbefehl in einem 45-Punkte-Verkaufsvorbereitungsdokument ausführen? Wenn Ihr Kundenservicemitarbeiter am Empfang eines wütenden Anrufs ist, möchten Sie dann, dass er verzweifelt eine FAQ nach einer Antwort durchsucht, oder möchten Sie ihm die Möglichkeit geben, nur den relevanten Abschnitt anzuzeigen?
Aufbau einer nachhaltigen Wissensbasis
Wir haben gesehen, wie funktioniert bite-size knowledge cards für uns, weshalb wir wissen, dass sie auch für Sie funktionieren können. Es macht nicht nur das Auffinden der Informationen, die Sie wirklich benötigen, schneller und einfacher, sondern bedeutet auch, dass die Wissenspflege viel einfacher ist. Erfahren Sie mehr über die Vorteile der Einführung eines unternehmensweiten Wissensmanagementsystems.
Durch die Implementierung eines Kurzformat-Ansatzes zur Wissensdatenbankarchitektur entfällt die ständige Notwendigkeit, völlig neue Dokumentationen hochzuladen. Ein einsetzendes Update in einem 20-seitigen Dokument bedeutet, dass Sie das gesamte Dokument erneut hochladen müssen und sicherstellen müssen, dass jeder über die Änderung informiert ist, da sie im neunten Punkt auf Seite 12 vergraben ist.
Alternativ kann ein einsetzendes Update in einem vier-Satz-wissensstück in Sekunden erfolgen. Dieser Ansatz macht es auch viel einfacher, bite-size Informationen zu verifizieren, um ihre Genauigkeit sicherzustellen, als längere Dokumente zu verifizieren, da jedes Stück Wissen individuell als korrekt verifiziert werden kann – und die Verifizierung ist letztendlich der Kern der Schaffung eines Wissensnetzwerks, dem jeder vertrauen kann.
Sicher, wir wissen, dass dies ironischerweise viele Worte sind, um zu erklären, warum kurzes Denken der bessere Ansatz zur Wissensarchitektur ist, also hier ist das tl;dr: bite-size Inhalte sind einfacher hinzuzufügen, einfacher zu aktualisieren, einfacher zu verifizieren und einfacher zu suchen. Denken Sie daran als Vokabelkarten vs. das Wörterbuch: eines hat alles, hilft Ihnen aber nicht, sich auf die nächste Woche zu prüfende Quiz vorzubereiten, während das andere genau das ist, was Sie brauchen, um durch das Quiz zu kommen, damit Sie zum Midterm und zum Finale durchkommen können und flexibel genug ist, um auf eine Million verschiedene Arten umorganisiert zu werden. Wofür würden Sie sich entscheiden?
Als Google 2012 sein Knowledge Graph auf den Suchergebnisseiten (SERPs) einführte, wurden seine Featured Snippets (diese kurzen, relevanten Datenpunkte, die ganz oben auf der Seite angezeigt werden) zur ersten Anlaufstelle für alle, die eine schnelle Antwort benötigten. Stark auf das Scraping von Daten von Seiten wie Wikipedia angewiesen, konnte Google Daten nutzen, die von anderen zusammengestellt wurden, um Sie in ihrem Ökosystem zu halten – ein Segen für einen werbegestützten Einnahmestrom. Aber etwas anderes geschah ebenfalls: der Verkehr zu Wikipedia nahm ab. Während jeder Statistiker im Recht wäre, uns daran zu erinnern, dass Korrelation nicht gleich oder impliziert Kausalität, können wir auch unser eigenes Verhalten betrachten, um einen Eindruck davon zu bekommen, was passiert ist. Wenn alles, was Sie wissen müssen, sagen wir, wer in diesem Jahr den Nobelpreis für Physik gewonnen hat und die Antwort ganz oben auf der Seite steht, ist es nicht nötig, weiter durch die anderen 105 Millionen Ergebnisse zu suchen.
Wir wissen das instinktiv, aber wenn es um unsere Wissensportale geht, richten wir sie oft so ein, dass sie als Archive fungieren, anstatt als Möglichkeit, die Informationen, die wir benötigen, leicht anzuzeigen. Deshalb – und das könnte schwierig zu hören sein – müssen wir unseren gesamten Ansatz komplett überdenken.
Wenn Ihr Unternehmenswissensportal wie die meisten ist, müssen Sie bei einer Frage a) genau wissen, wonach Sie suchen, oder b) Sie müssen durch Hunderte (oder Tausende!) von Wörtern in mehrseitigen FAQs oder PDFs suchen, um eine Antwort zu finden, die irgendwo in ihnen vergraben ist.
Control-F war entscheidend, um dieses Setup zu ermöglichen, aber warum sollten Sie eine effektiv als Umgehung betrachtete Methode verwenden, nur um eine einfache Antwort zu erhalten? Es liegt nicht nur an dem Mitarbeiter, das Wissen auszubuddeln (was einen nicht unerheblichen Zeitraum in Anspruch nehmen kann), es bedeutet auch, dass jedes Mal, wenn sich etwas an diesem Wissen ändert, das Unternehmen ein völlig neues PDF, Video oder eine FAQ hochladen muss. Das verschwendet Zeit – und Budgets.
Die bessere Lösung ist, Ihre Wissensarchitektur vollständig zu überdenken und sich in Richtung kurzformatiger, leicht konsumierbarer (und aktualisierbarer), diskreter Wissensstücke zu bewegen.
Suche und Rettung
„Schau, es ist nicht so schlimm“, sagen Sie wahrscheinlich gerade, „es erfüllt seinen Zweck!“ Also lassen Sie uns darüber sprechen. Das ist nicht einmal das erste Mal, dass wir darüber auf dem Guru-Blog gesprochen haben. Vor fast drei Jahren haben wir darauf hingewiesen, dass:
Vertriebler verbringen bis zu ein Drittel ihrer Tage, um Informationen zu suchen, die sie für ihre Arbeit benötigen. Informationen werden bei Bedarf benötigt, und die aktuellen Lösungen sind nicht für eine On-Demand-Welt ausgelegt. Dokumente und Wikis zwingen Sie dazu, Control+F zu verwenden, um Wörter zu finden, und lassen Sie dann die Antworten selbst zusammenpuzzeln.
Wenn Sie mit einem Kunden chatten und eine Frage beantworten müssen, haben Sie nicht die Zeit, um den aktuellen langen und ineffizienten Prozess zu durchlaufen, um die Antwort zu finden. Sie suchen das Dokument, das die richtige Antwort haben sollte, öffnen dieses Dokument, suchen nach einem Schlüsselwort, und nach all dem erscheint nicht Ihre Antwort, sondern Sie sehen, dass das Wort, das Sie eingegeben haben, fünfzehn Mal erscheint. Um die richtigen Informationen zu erhalten, müssen Sie alle Optionen durchklicken, während Ihr Kunde auf seine Antwort wartet.
Aber es geht über das bloße Verschwendet wertvoller Sekunden hinaus. Längere Inhalte sind einfach schwieriger zu durchsuchen als kürzere Inhalte. Lassen Sie uns das aus dem Bereich des Wissensmanagements herausnehmen und in einen Bereich bringen, mit dem wir uns alle identifizieren können: wie wir mit Inhalten zu Freizeitzeiten umgehen.
Hier ist eine Frage, deren Antwort Sie vielleicht wissen oder auch nicht: In welchem Jahr hatte Die Simpsons Premiere? Sie ziehen Wikipedia auf, geben „Die Simpsons“ ein und erhalten diese Seite mit über 17.000 Wörtern. Sie verlassen sich auf Ihr bewährtes Control-F und suchen nach „Premiere“ und das passiert:
Warten Sie, was? Stellt sich heraus, dass Sie nach „Release“ suchen mussten:
Nicht nur mussten Sie genau wissen, wie diese (hochorganisierte, sollten wir anmerken) Seite aufgebaut ist, sondern Sie mussten auch genau die Terminologie kennen, die die Autoren verwendet haben, um ein Startdatum anzugeben. In der Zwischenzeit, wenn Sie zu Google gehen und einfach „Simpsons Premiere“ eingeben, erhalten Sie dies:
Suchen Sie nach „Simpsons Veröffentlichung“ und Sie erhalten dieselben Informationen, wenn auch etwas anders dargestellt:
So oder so ist das Ergebnis hilfreich, schnell und vor allem unabhängig von der genauen Formulierung, die Sie verwendet haben, leicht zu finden. Sie mussten nicht einmal Control-F verwenden.
Ich habe immer noch nicht gefunden, was ich suche
Jetzt lassen Sie uns diese Diskussion wieder auf das Wissensmanagement lenken. Ihre eng gedruckten PDFs mit einer Schriftgröße von 10pt und FAQ mit 48 Punkten sind großartig – um Druckkosten zu sparen. Sie sind nicht ideal, um sich genau auf das zu konzentrieren, was Ihre Mitarbeiter wissen müssen, egal ob es sich um Informationen zu Leistungen bei der Einarbeitung, Produktdokumentation zum Launch oder sogar darum handelt, das richtige Informationsblatt zu finden, das verteilt werden soll.
Lustigerweise, je mehr wir unser Wissen digitalisiert haben, desto mehr mussten wir auf Umgehungen zurückgreifen, um das, was wir finden mussten, tatsächlich zu lokalisieren. Diese vielgehassten Lehrbücher Ihrer Jugend? Das Register war der Teil, mit dem Sie die meiste Zeit verbracht haben. Schließlich sagte es Ihnen genau, wo Sie finden konnten, was Sie benötigten – und was Sie ignorieren sollten – und beinhaltete normalerweise auch kontextuelle Aufschlüsselungen (z. B.: Die Mondlandung, die Reaktion der UdSSR darauf).
Jetzt? Wir machen uns Arbeit, die Computer und KI effizienter erledigen können, wenn wir sie nur lassen. Ihr Wissen in mundgerechte Portionen zu speichern bedeutet, dass jede kontextuelle Suche viel schneller geschehen kann. Viele Unternehmen sprechen über ihre Maschinenlern- und KI-Fähigkeiten in der Unternehmenssuche – aber all diese Lösungen sind nutzlos, wenn sie nur ein 30-seitiges Dokument anzeigen können, das Ihre Mitarbeiter immer noch durchsehen müssen.
Wenn Dokumente nicht zum Drucken bestimmt sind, gibt es keinen Grund, sie nicht in einzelne Komponenten zu unterteilen, um eine bessere Wissensreferenzerfahrung zu ermöglichen. Andernfalls zahlen Sie als Unternehmen möglicherweise Ihre Mitarbeiter dafür, dass sie die manuelle Arbeit des Durchsuchens von 50 hervorgehobenen Vorkommen des Wortes „Sicherheit“ in einem Produktdokument erledigen – und sie finden möglicherweise immer noch nicht, wonach sie suchen, weil sie nicht mehr Kontext in eine Control-F-Suche einbringen können.
Dieser Ansatz kommt nicht nur denen zugute, die Wissen hinzufügen und pflegen; es hilft auch Ihrem Vertriebsteam enorm. Wenn ein Verkäufer versucht, einen Deal abzuschließen, möchten Sie dann, dass sie sofortigen Zugriff auf spezifische Informationen haben oder... einen Suchbefehl in einem 45-Punkte-Verkaufsvorbereitungsdokument ausführen? Wenn Ihr Kundenservicemitarbeiter am Empfang eines wütenden Anrufs ist, möchten Sie dann, dass er verzweifelt eine FAQ nach einer Antwort durchsucht, oder möchten Sie ihm die Möglichkeit geben, nur den relevanten Abschnitt anzuzeigen?
Aufbau einer nachhaltigen Wissensbasis
Wir haben gesehen, wie funktioniert bite-size knowledge cards für uns, weshalb wir wissen, dass sie auch für Sie funktionieren können. Es macht nicht nur das Auffinden der Informationen, die Sie wirklich benötigen, schneller und einfacher, sondern bedeutet auch, dass die Wissenspflege viel einfacher ist. Erfahren Sie mehr über die Vorteile der Einführung eines unternehmensweiten Wissensmanagementsystems.
Durch die Implementierung eines Kurzformat-Ansatzes zur Wissensdatenbankarchitektur entfällt die ständige Notwendigkeit, völlig neue Dokumentationen hochzuladen. Ein einsetzendes Update in einem 20-seitigen Dokument bedeutet, dass Sie das gesamte Dokument erneut hochladen müssen und sicherstellen müssen, dass jeder über die Änderung informiert ist, da sie im neunten Punkt auf Seite 12 vergraben ist.
Alternativ kann ein einsetzendes Update in einem vier-Satz-wissensstück in Sekunden erfolgen. Dieser Ansatz macht es auch viel einfacher, bite-size Informationen zu verifizieren, um ihre Genauigkeit sicherzustellen, als längere Dokumente zu verifizieren, da jedes Stück Wissen individuell als korrekt verifiziert werden kann – und die Verifizierung ist letztendlich der Kern der Schaffung eines Wissensnetzwerks, dem jeder vertrauen kann.
Sicher, wir wissen, dass dies ironischerweise viele Worte sind, um zu erklären, warum kurzes Denken der bessere Ansatz zur Wissensarchitektur ist, also hier ist das tl;dr: bite-size Inhalte sind einfacher hinzuzufügen, einfacher zu aktualisieren, einfacher zu verifizieren und einfacher zu suchen. Denken Sie daran als Vokabelkarten vs. das Wörterbuch: eines hat alles, hilft Ihnen aber nicht, sich auf die nächste Woche zu prüfende Quiz vorzubereiten, während das andere genau das ist, was Sie brauchen, um durch das Quiz zu kommen, damit Sie zum Midterm und zum Finale durchkommen können und flexibel genug ist, um auf eine Million verschiedene Arten umorganisiert zu werden. Wofür würden Sie sich entscheiden?
Erleben Sie die Leistungsfähigkeit der Guru-Plattform aus erster Hand – machen Sie unsere interaktive Produkttour